NextJS의 Hydrate란
2026-01-25
페이지 라우터에서 앱 라우터로, 뭐가 좋아졌을까?
나는 App Router가 표준이 되면서부터 사용했기 때문에, App router만 사용을 해봤다.
왜 Next는 Page Router가 가진 관습을 버리고, App Router를 채택했을까? 그게 궁금했다.
페이지 라우터에서 앱 라우터로 넘어오면서 “좋아진 점”으로 가장 자주 언급되는 말 중 하나가 이거다.
서버 컴포넌트가 기본이 되면서
서버 / 클라이언트 경계가 명확해졌다.
이 문장을 처음 봤을 때, 솔직히 이런 생각이 들었다.
이게… 왜 좋은 거지?
무심코 지나치기엔 자주 보이는 이야기라서, 직접 이유를 찾아보다가 하나의 핵심 개념을 알게 됐다.
바로 Partial Hydration이다.
그래서 이번 글에서는, 그 이야기를 하기 전에 꼭 짚고 넘어가야 할 Hydration 개념부터 정리해보려고 한다.
Hydration이란 무엇인가?
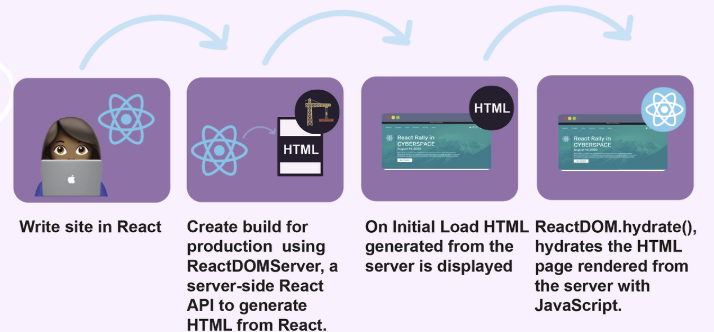
Hydration이란,
서버 사이드에서 렌더링된 HTML과 클라이언트에서 내려받은 React 자바스크립트 코드를 서로 연결(매칭)시키는 과정을 말한다.
조금 더 풀어 말하면,
- 서버에서 미리 렌더링된 정적인 HTML을 클라이언트에게 보내고
- 이후 번들링된 React JS 파일을 다시 내려보낸 뒤
- 클라이언트에서 HTML DOM과 React JS를 하나하나 매칭시키는 과정
이 전체를 Hydrate(수화) 라고 부른다.
이 과정이 왜 필요한지 이해하려면, 먼저 React가 웹 페이지를 어떻게 구성하는지부터 짚고 가야 한다.
React의 웹 페이지 구성 원리
React는 기본적으로 자바스크립트만으로 웹 화면을 구성한다.
그래서 실제 HTML 파일을 열어보면,
안에 콘텐츠는 하나도 없고 뼈대만 있는 경우가 대부분이다.
(Client Side Rendering이 SEO에 불리한 이유이기도 하다.)
<!-- public/index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
</head>
<body>
<div id="root"></div>
</body>
</html>아마 리액트 프로젝트를 처음 세팅할 때 수 없이 봤던 익숙한 HTML 코드일 것이다.
이렇게 내용이 비어 있는 HTML 문서와 JS 파일들을 모두 클라이언트로 보낸 뒤, 클라이언트에서 자바스크립트 코드를 실행해 웹 화면을 그리게 된다.
페이지가 그려진 이후에 발생하는 모든 클릭, 입력, 이벤트 처리 역시 전부 자바스크립트로 동작한다.
// src/index.js
import React from "react";
import ReactDOM from "react-dom";
import App from './src/App';
ReactDOM.render(<App />, document.getElementById("root"));public/index.html에는 root라는 빈 껍데기만 있고, 실제 화면 구성은 전부 src/index.js에서 이루어진다.
React는 이 root DOM을 찾아 그 하위에 컴포넌트 트리를 통째로 주입하는 방식이다.
Next.js의 웹 페이지 구성 원리
Next.js는 이 흐름이 조금 다르다.
Next.js는 클라이언트로 보내기 전에, 서버 사이드에서 이미 웹 페이지를 한 번 렌더링한다. (Pre-Rendering) 그리고 그 결과로 만들어진 HTML document를 클라이언트에게 먼저 전달한다.
여기서 중요한 포인트가 하나 있다.
👉 이 시점의 HTML은 화면은 보이지만, 자바스크립트가 하나도 없는 상태다.
즉, 버튼은 보이지만 클릭해도 아무 일도 안 일어나고 입력창은 보이지만 이벤트 리스너가 없고 React 컴포넌트로서의 동작은 전혀 없는
말 그대로 “보이기만 하는 빈 껍데기” 상태다.
그럼 이 페이지는 어떻게 다시 살아날까?
Next.js 서버는 Pre-Rendering된 HTML을 클라이언트로 보낸 직후, 곧바로 React가 번들링된 자바스크립트 코드들을 다시 내려보낸다.
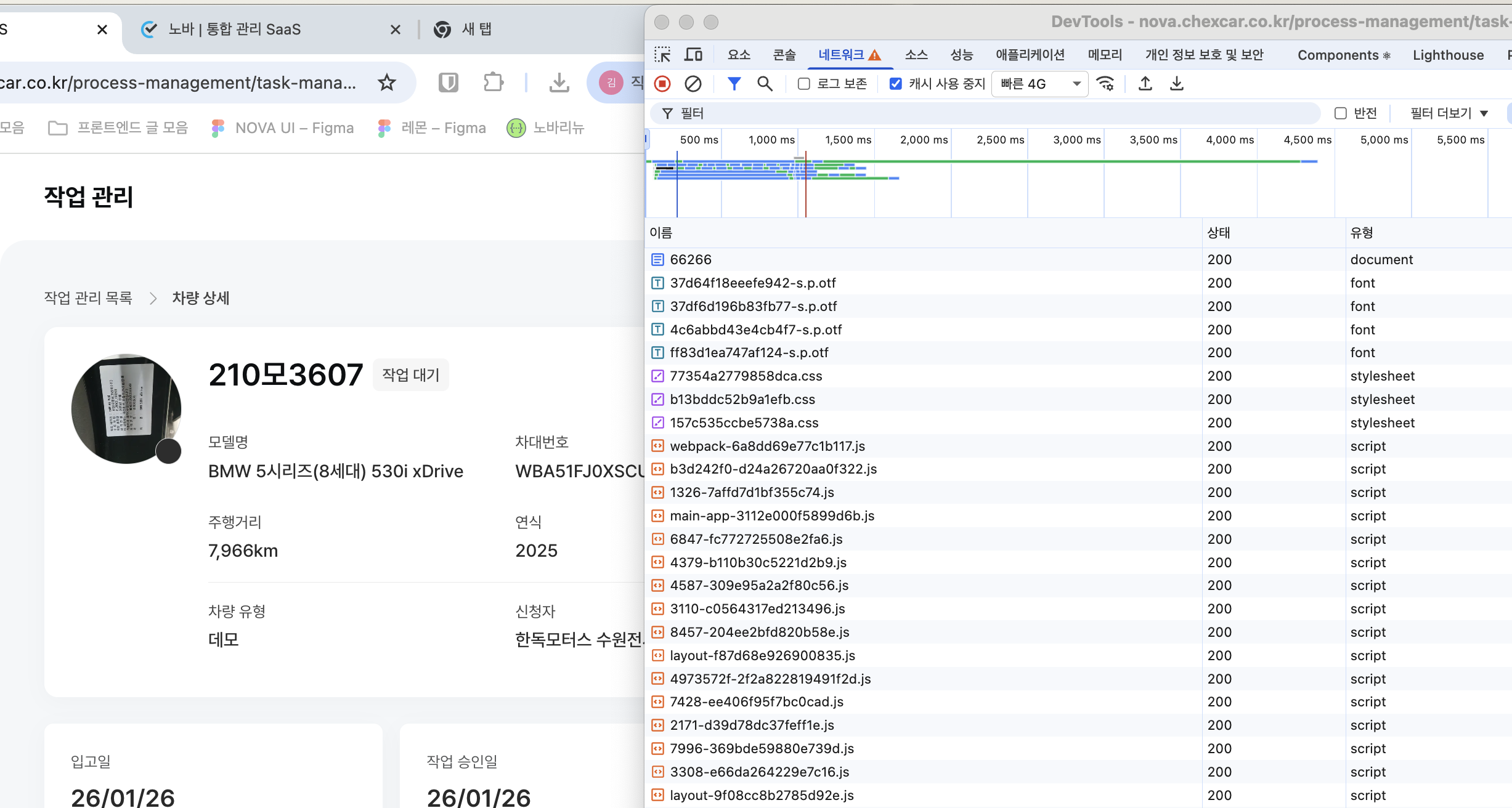
브라우저의 Network 탭을 보면,
가장 먼저 document 타입의 HTML 파일이 내려오고, 이후 React 코드가 담긴 JS 파일들이 chunk 단위로 다운로드된다
그리고 이 자바스크립트 코드들이 이미 존재하던 HTML DOM 위에서 다시 한 번 실행되면서, 각자 자기 자리를 찾아 DOM과 매칭된다.
이 과정을 바로 Hydration이라고 부른다.
자바스크립트 코드들이 DOM 위에 필요한 기능들을 하나씩 채워 넣는 모습이 마치 물을 채우는 것 같다고 해서 Hydrate(수화)라는 이름이 붙었다고 한다.
아마 위 GIF처럼, 페이지를 새로 열 때 잠깐 스타일이 깜빡이는 현상을 Next.js에서 한 번쯤은 봤을 것이다.
이건 HTML은 이미 보이는데, 자바스크립트가 아직 Hydration을 끝내지 못해서 스타일이나 폰트가 늦게 적용되며 생기는 현상이다.
(정확히 말하면, 웹 폰트는 자바스크립트로 외부 서버에 요청해 받아오는데 Hydration 이전에는 이 요청이 아직 이루어지지 않아 기본 폰트로 잠깐 보이게 된다.)
서버에서도 한 번, 클라이언트에서도 한 번… 비효율 아닌가요?
이쯤 되면 이런 생각이 들 수 있다.
서버에서 한 번 렌더링하고 클라이언트에서 또 한 번 렌더링하면 오히려 비효율적인 거 아닌가요?
겉으로 보면 그렇게 보일 수도 있다.
하지만 실제로는, 서버에서 빠르게 Pre-Rendering 된 HTML을 먼저 내려보내 유저에게 아주 빠르게 화면을 보여줄 수 있다는 장점이 훨씬 크다.
게다가 이 HTML은 모든 자바스크립트가 빠진 아주 가벼운 문서이기 때문에 초기 로딩 속도도 빠르다.
이 장점만으로도 “두 번 렌더링”이라는 단점을 충분히 상쇄하고도 남는다.
더 중요한 점은, 클라이언트에서 이루어지는 Hydration은 실제로 화면을 다시 그리는 렌더링이 아니라는 것이다.
Hydration의 목적은 기존 DOM을 재사용하면서 이벤트 리스너 같은 자바스크립트 속성만 연결하는 것이기 때문에, 브라우저의 Paint 단계까지 다시 호출하지 않는다. (즉, 화면을 다시 그리지 않는다.)
Hydration은 Next.js에서만 일어나는 과정일까?
사실 Hydration은 Next.js에만 존재하는 개념은 아니다.
이건 React 자체에서 제공하는 기능이다.
보통 리액트 프로젝트를 시작할 때 우리가 가장 먼저 작성하는 코드가 바로 이거다.
ReactDOM.render(element, container, [callback]);ReactDOM.render()는 특정 컴포넌트를 지정한 DOM 요소 하위에 새로 렌더링해서 DOM 구조 자체를 만들어주는 역할을 한다
반면에 Hydration은 조금 다르다.
ReactDOM.hydrate(element, container, [callback]);ReactDOM.hydrate()는 새로운 DOM을 만들지 않고 이미 존재하는 DOM Tree를 기준으로
해당되는 DOM 요소를 찾아 이벤트 리스너 같은 자바스크립트 속성만 부착한다
즉, “페이지를 새로 그리는 것”이 아니라 **“이미 있는 페이지에 생명을 불어넣는 과정”**에 가깝다.
다시 돌아와서, Next는 왜 Page Router를 버렸을까?
사실 지금 이 시점에 굳이 Hydration 이야기를 따로 정리한 이유가 있다.
최근에 웹 성능 최적화 관련 포스팅을 보다가, Page Router/App Router의 Hydration 과정 차이와 그 안에서 벌어지는 흥미로운 점들을 발견했다.
특히, 왜 서버 컴포넌트가 기본이 되면 Partial Hydration이 가능해지고 서버 / 클라이언트 경계가 명확해지는지 이 모든 이야기가 결국 Hydration 구조와 깊게 연결되어 있었다.
그래서 다음 회차에서는 이 Hydration을 더 쪼개서 다루는 Partial Hydration 이야기를 이어서 해보려고 한다.